
Self-driving driving cars will change urban mobility significantly, but there are still challenges to overcome. One of them is demonstrating the safety of AI-based Automated Driving Systems (ADS).
The development of safe Automated Driving Systems (ADS) is the great technological challenge of our time. Tens of billions of dollars have been dedicated to the problem since the DARPA grand challenges in 2004-2005.
As an industry, we’ve made some impressive leaps forward. In the US, giants like Cruise, Waymo, and Uber drive many thousands of miles a day autonomously over complex Operational Design Domains.
More broadly, modern passenger cars have felt the impact: in January 2021, the UNECE Automated Lane Keeping System (ALKS) regulation will go into effect, enabling European Type Approval for the first SAE Level 3 system. ALKS will, in its current form, help drivers safely navigate heavy traffic and continue the trend for ADAS features improving safety on the roads.
As these systems move from a proof of concept to a functionally and nominally safe, robust ADS, it has become clear that there is a long way to go until the technology will be broadly deployed. The major variable is robustly demonstrating the safety of these AI-based ADS. The size, difficulty and expense of this remaining challenge has been a major factor in the hype around self-driving fizzling out over the past year.
Myth-busting
In the early days, miles driven per disengagement was the measure of safety performance for an ADS. Disengagements and ‘unexpected events’ were the primary mechanism for discovering problems with the stack. The disengagement myth, of disengagements as the main metric of progress and real-world driving as the primary validation technique, was shattered early.
One of the reasons was the high number of driven miles required to discover all potential “corner cases”. The Figure below illustrates the scenario occurrence probability versus the number of miles driven. Point 1 is an approximation of the miles driven so far by the industry, whereas point 2 estimates the amount of years that it will take to reach 1 billion miles with the current pace.
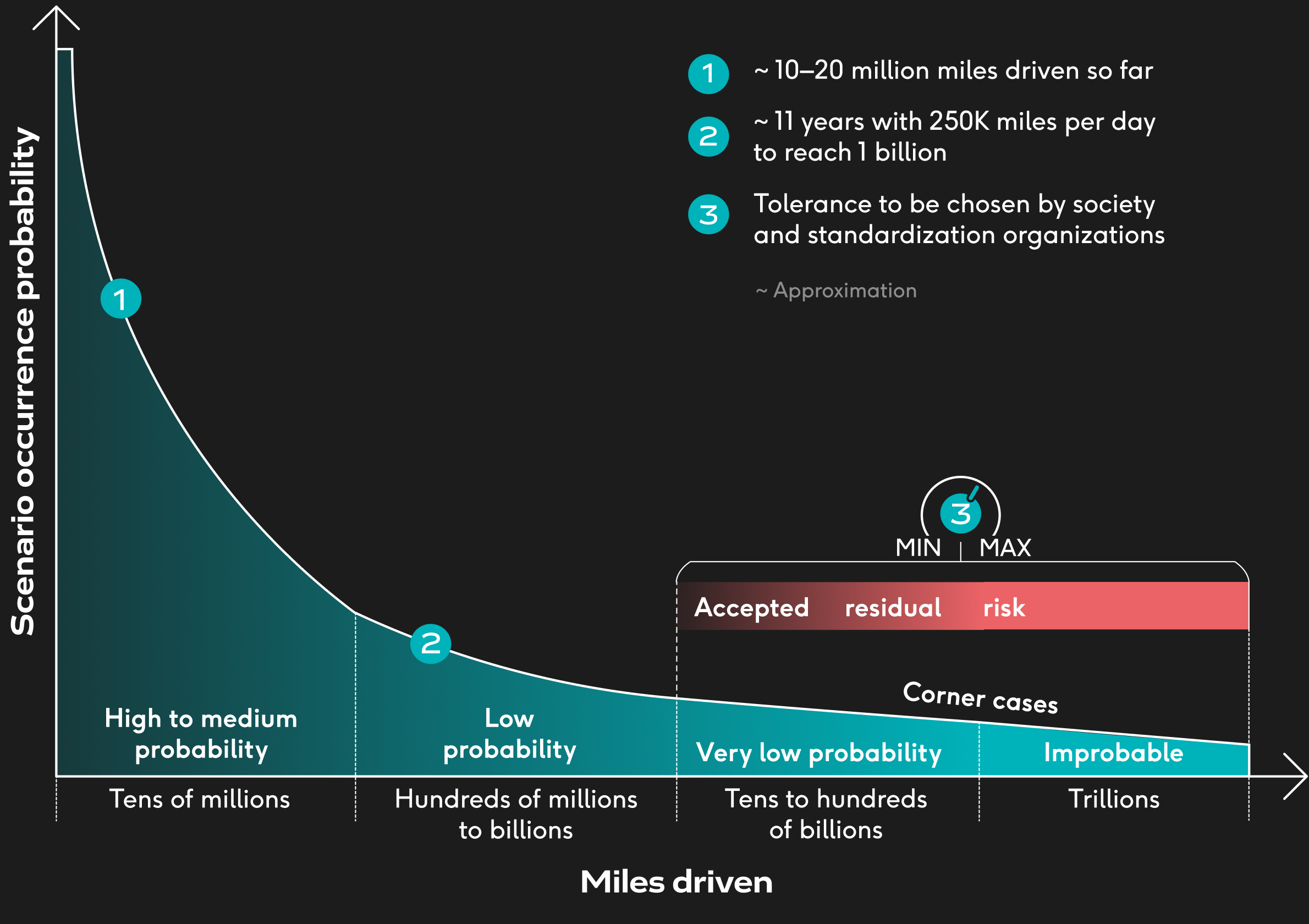
Intuitively, the number of miles driven can be accelerated with simulation. In simulation, an ADS can be given the ‘ride of its life’: packing more thrills and spills into a synthetic mile than you would see in thousands of real world miles.
Simulation may hold the key but, at Five, we have come to understand that unlocking the value of simulation comes with its own set of challenges.
The devil’s in the details
When it comes to simulation, we have a choice to make. Do we run a high fidelity simulation with full photo and material-realistic rendering or a low fidelity simulation instead? Both come with significant implications on measuring safety.
Option 1: High Fidelity Simulation
For high fidelity simulation, we will need to digitize and render vast areas of the world in virtual space. Then, if we want to present the entire ADS with inputs it would receive if tested in the real world, we will need accurate models of all the sensors in a vehicle to generate those inputs. Needless to say, this is a computationally (and financially) gargantuan task and really hard to do faster than real-time. But imagine it was done, it still leaves the developer exposed to the domain adaptation problem.
CNNs turn out to be extremely sensitive to the statistics of their input domain and constructing synthetic images that stimulate the same outputs as real world images remains a general problem in deep learning right now.
Option 2: Low Fidelity Simulation
The alternative, low fidelity simulation, requires us to generate only the feature representation of the interface between the Sense and the Plan components; no need to render anything or model any of the sensors. Often referred to as ‘headless’ simulation, this removes the computationally expensive part of the simulation and, since Sense isn’t tested at all, the expensive parts of running an ADS.
The problems with this paradigm are twofold:
- Firstly, since no testing of the Sense component is performed in simulation at all, separate real-world testing of the Sense component is still needed in large quantities, meaning high expense, long timescales and low replicability.
- Secondly, in presenting the Plan component with a perfect feature space representation of a scenario in simulation, we are not testing that component as it would be exercised in the real world, which always contains some perception errors. All perception systems are imperfect and a planner needs to be robust in the presence of such errors.
We call this the Simulation Fidelity Problem.
From Bad to Worse
As if this wasn’t bad enough, there lies a second challenge when it comes to simulation realism: saliency.
When all our testing was in the real world, we could more-or-less guarantee that it was relevant, since we were driving within our target Operational Design Domain (ODD), so failures in real world driving need fixin’.
Now, if we push our testing into a simulated world, we can repeatedly reproduce that system error as a scenario – either hand-crafted or extracted from a real-world encounter – and fix the problem. That’s great, but we can still go much further. In simulation, we are able to create just about any traffic scenario that we could encounter in the real world. This is extremely powerful.
The problem comes, however, when we ask ourselves two questions:
- Is this scenario that I just created likely to happen in the real-world?
- If it did, would even a human driver have been able to negotiate it successfully?
The problem we have just elucidated is essentially this: a single scenario in simulation gives a so-called micro-level assessment of safety, whereas what we seek is a macro-level assessment of safety, based on all the scenarios one could encounter. Knowing if a scenario is relevant for your macro-level assessment is what we call the Simulation Saliency Problem.
Addressing the simulation fidelity problem and the simulation saliency problem are of the highest priority for our industry.
At Five, we are tackling both these problems – the simulation fidelity and simulation saliency problems – as key features of our cloud-based development and assurance platform. This helps developers to find problems with an ADS faster than traditional methods and get better coverage of the driving domain through ensuring all simulations are salient.
We firmly believe, however, that these challenges are much bigger and a single ‘stakeholder’ cannot solve them alone. The community needs to come together to focus on initiatives like The Autonomous.
